Acelerando a produtividade em data science
Ao utilizar a I.A no dia a dia podemos agilizar o processo dos nossos projetos como exploração, visualização e até apresentação dos projetos, o que economiza tempo e recursos. Eliminando etapas mais repetitivas e trazendo uma maior eficiência no dia a dia, e no projeto abaixo vamos fazer exatamente isso.
Projeto: analisar os dados da Boltfunds uma empresa de investimento voltada para área de energia.
Objetivo:
- Exploração
- Análise de visualização
- Encontrar padrões nos dados
- Montar apresentação
Nesse projeto vamos usar dois arquivos do tipo CSV que apresentam dados brutos:
Resumo_Mundial.csv
Sobre: o conjunto de dados que contém informações globais sobre produção, consumo, importação e exportação de energia elétrica, bem como variações nas reservas, apresentado dados específicos por fonte de energia. Os valores estão em quatrilhões de BTU.
Producao_total.csv
Sobre: o conjunto de dados contém informações sobre a produção total de energia elétrica ao longo dos anos para diferentes países e continentes. Os valores estão em quatrilhões de BTU
Principal motivo para uso de I.A nesses dados:
- Falta de conhecimento avançado em Python
- Prazo muito curto para entrega
Começamos nosso projeto importando o nosso dataset e para isso, vamos criar uma variável que vai receber como valor a url dos dados:
url_resumo_mundial = ‘https://raw.githubusercontent.com/alura-cursos/IA-produtividade-DS/main/Dados/Resumo_mundial.csv’
url_producao = ‘https://github.com/alura-cursos/IA-produtividade-DS/raw/main/Dados/Producao_total.csv’
Agora vamos usar o Gemini do google com o seguinte prompt:
🤖 Prompt:
“Quero que você atue como um cientista de dados e codifique para mim. Estou desenvolvendo um projeto de Data Science focado no tema de consumo e produção de energia elétrica pelo mundo.
Tenho as url de 2 datasets no formato csv salvas no meu notebook colab. As variáveis são as seguintes: “url_resumo_mundial” e “url_producao”
Escreva o código em Python para importar os dados.”
O resultado do prompt veio um pouco diferente, fiz alguns ajuste resultando no código abaixo:
import pandas as pd
# Importar o dataset de resumo mundial
resumo_mundial = pd.read_csv(url_resumo_mundial)
# Importar o dataset de produção
producao = pd.read_csv(url_producao)
Exploração de resumo_mundial
Prompt:
“Agora vamos começar a trabalhar com o dataframe “resumo_mundial”, escreva um código que permita executar a exploração desses dados.”
O resultado do prompt foi uma serie de funções que podemos usar para explorar o nosso dataset
# Importar o dataset de resumo mundial
resumo_mundial = pd.read_csv(url_resumo_mundial)
# Exibir as primeiras 5 linhas do dataframe
resumo_mundial.head()
# Exibir as últimas 5 linhas do dataframe
resumo_mundial.tail()
# Exibir as estatísticas descritivas do dataframe
resumo_mundial.describe()
# Exibir o tipo de dados de cada coluna do dataframe
resumo_mundial.dtypes
# Exibir o número de linhas e colunas do dataframe
resumo_mundial.shape
# Exibir os nomes das colunas do dataframe
resumo_mundial.columns
# Exibir os valores únicos de cada coluna do dataframe
resumo_mundial.nunique()
# Exibir a correlação entre as colunas do dataframe
resumo_mundial.corr()
# Exibir as primeiras 5 linhas do dataframe
resumo_mundial.head()

resumo_mundial.tail()
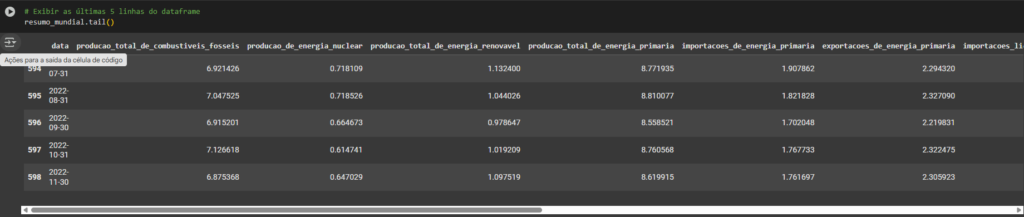
Vou resumir para o post para não ficar tão grande, mas básicamente com uso dessas funções podemos explorar nosso dataset, por exemplo os comandos head() e tail(), com esses comandos podemos analisar as 5 primeiras linhas e as 5 últimas linhas e com isso já podemos perceber que possuímos uma base de dados coletada mensalmente, que vai de um período de 50 anos,ou seja, nossa tabela começa no ano de 1973 e vai até 2022.
Resumo da nossa Exploração e Estatísticas dos dadosresumo_mundial.describe()
Retorna estatísticas descritivas (como média, desvio padrão, valor mínimo, máximo e quartis) para colunas numéricas.
resumo_mundial.dtypes
Exibe o tipo de dado (int, float, object, etc.) de cada coluna.
resumo_mundial.shape
Retorna uma tupla com o número de linhas e colunas do DataFrame (ex: (100, 5)).
resumo_mundial.columns
Lista o nome de todas as colunas do DataFrame.
resumo_mundial.nunique()
Mostra quantos valores únicos existem em cada coluna.
resumo_mundial.corr()
Calcula a correlação entre colunas numéricas, mostrando a força da relação linear entre elas (valores entre -1 e 1).
Aprofundando as nossas análise ultilizando gráficos
Correlação entre colunas
🤖 Prompt:
Ao usar “resumo_mundial.corr()” obtive um dataframe com os dados referentes à correlação de 12 colunas presentes no dataframe “resumo_mundial”.
“Crie um código para visualizar a correlação em uma figura utilizando a biblioteca seaborn.”
Novamente precisei fazer alterações no código resultando código abaixo
import seaborn as sns
# Importar o dataset de resumo mundial
resumo_mundial = pd.read_csv(url_resumo_mundial)
# Obter o dataframe de correlação
correlacao = resumo_mundial.corr()
# Visualizar a correlação em uma figura
sns.heatmap(correlacao, annot=True, cmap="RdYlGn")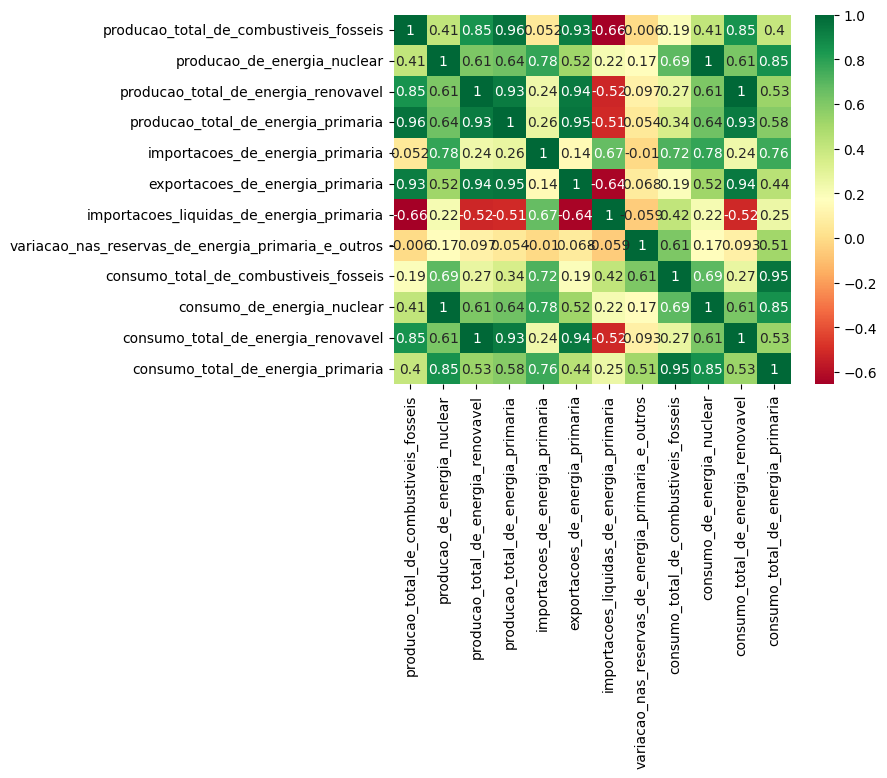
Gráfico de calor heatmap da biblioteca Seaborn.
Este gráfico mostra a correlação entre as 12 colunas do dataframe “resumo_mundial”. A cor de cada célula na matriz representa o valor da correlação entre as duas colunas correspondentes. As células na diagonal principal são sempre 1, pois representam a correlação de uma coluna com ela mesma. As células acima e abaixo da diagonal principal represetam a correlação entre pares de colunas diferentes.
Análise
A análise das correlações revelou que a produção total de energia primária está altamente correlacionada com a produção de combustíveis fósseis, energia nuclear e energia renovável, pois é a soma dessas três fontes. O mesmo vale para o consumo total de energia primária, que é composto pelos consumos dessas mesmas fontes. As correlações variam, mas todas são positivas (ex: 0,95, 0,85, 0,53).
Além disso, há forte correlação entre exportações de energia e produção total, o que é lógico, já que países exportadores precisam garantir o próprio abastecimento. Já as importações de energia mostram correlação positiva com o consumo total, porém menos intensa.
Por fim, observou-se correlação perfeita (valor 1) entre produção e consumo de energia nuclear e renovável, indicando que toda energia produzida dessas fontes foi consumida. A análise presume que os dados da Boltfunds são corretos.